
Spelen met bottlenecks
De afgelopen paar maanden is Wouter Leeuw, data-science stagiair bij AnalyzeData – een van de bedrijven met wie wij ons kantoorpand mogen delen, los gegaan op een productie dataset van Berco Car Carpets. Het doel van het onderzoek? Het vormgeven van een simulatiemodel dat de daadwerkelijke productiestroom zo correct mogelijk weergeeft en uitzoeken waar verbeterpunten zouden kunnen liggen. Afgelopen dinsdag presenteerde hij zijn resultaten bij Berco.
We hebben al vaker geblogd over het belang van kwalitatief goede data, de mogelijkheden van business events en hoe wij process mining zien. Dit onderzoek was een mooie manier om af te tasten wat er mogelijk is met de data die we momenteel al verzamelen in en rondom Berco’s productiehallen. Voor ons ook een test of we de goede richting op gaan.
De basis
Aan de basis van dit onderzoek ligt, uiteraard, de data. Deze omvatte meer dan 62.800 events, gekoppeld aan meer dan 6.175 verschillende werkorders. Na het definiëren van gebruikte en benodigde begrippen, werd de data opgeschoond. Dit wordt gedaan om dingen die per toeval fout worden gelogd uit te sluiten van de analyse. Dit zou een vertekend beeld schetsen na aggregatie.
Om te testen of het uiteindelijk gemaakte simulatiemodel zich goed relateert aan de werkelijkheid, zijn er vooraf ook statistieken berekend, om als het ware een soort 0-meting te hebben. Bijvoorbeeld: Wat is de gemiddelde doorstroming? Wat is de gemiddelde productietijd per order? Een flinke afwijking van deze statistieken kan indiceren dat er iets fout zit in de data.
Het model
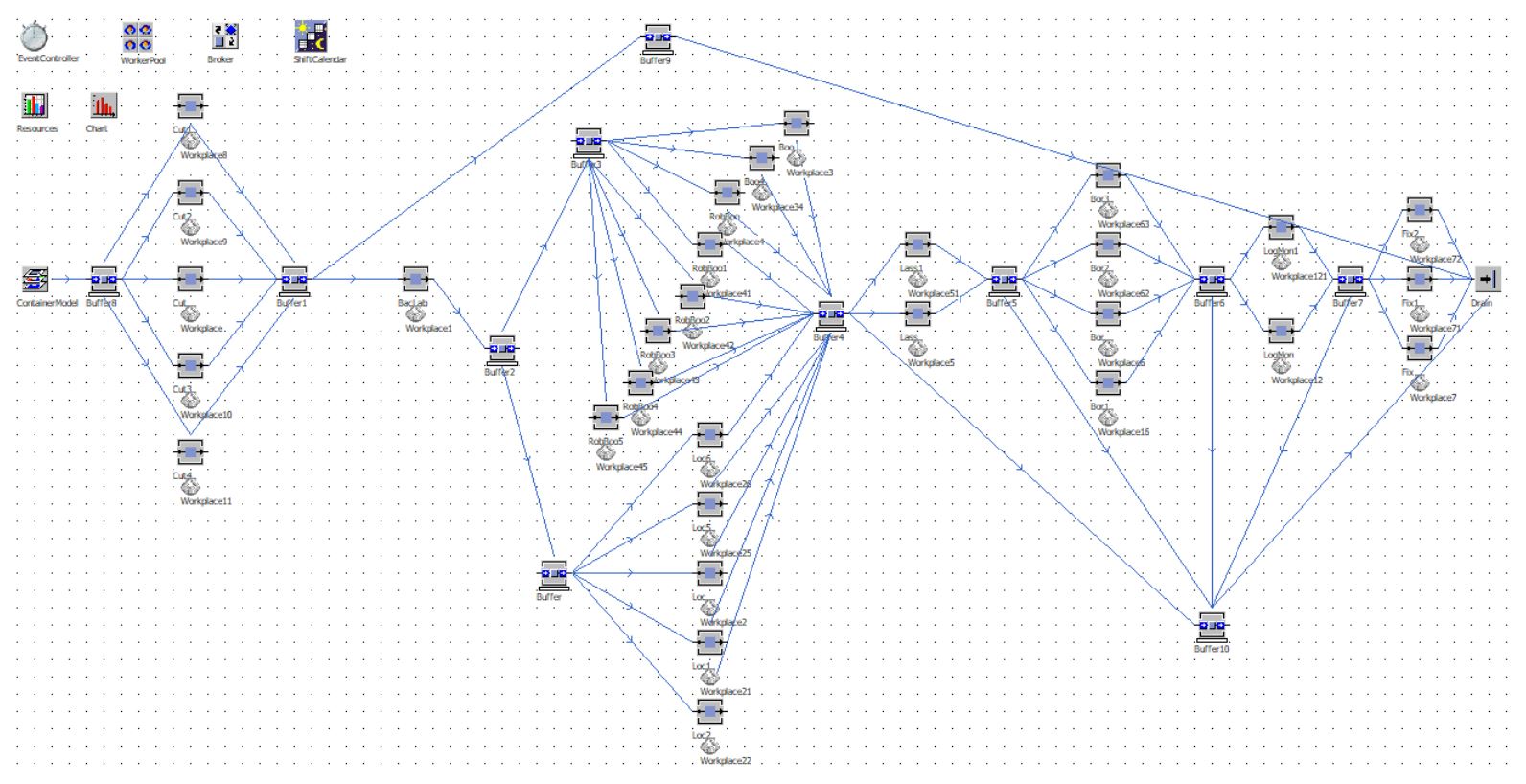
Toen deze basis er eenmaal lag, was het tijd voor ‘process extraction’; het vinden van het daadwerkelijke proces in de hal. Deze process flow is gevonden middels een varianten analyse over de event log, met gebruik van PM4Py. De uitkomst van deze variant analyse bestaat uit de verschillende paden die een werkorder door de fabriek kan nemen en hoe frequent deze paden genomen worden.
Gebaseerd op deze paden en de meest voorkomende start- en eindpunten, is er een algemeen productie model gevormd. Hierin is ook gekeken naar limitaties m.b.t. het parallel uitvoeren van bepaalde taken. Sommige werkposttaken kunnen of zullen nooit simultaan worden uitgevoerd.
Om te kunnen concluderen dat het procesmodel betrouwbaar en representatief is, zijn de meest voorkomende paden ernaast gelegd. Toen deze inderdaad het gemodelleerde proces volgden, bleek het procesmodel representatief.
Visualisatie en optimalisatie
En dan? De volgende stap was het vertalen van dit representatieve model naar een omgeving genaamd Plant Simulation. Plant Simulation is een computerprogramma van Siemens voor het modelleren, simuleren, analyseren, visualiseren en optimaliseren van productiesystemen en -processen. Een perfecte match met dit onderzoek dus.
Na het runnen van een aantal simulaties werd al snel duidelijk waar zich bottlenecks bevonden. Hier valt vervolgens mee te spelen; zo kun je ‘eenvoudig’ zien wat het effect zou zijn van een extra productiemachine of een extra ploeg medewerkers.
Conclusie
De overall conclusies die we kunnen trekken uit dit project:
- De data die we verzamelen is zeer waardevol
- De data wordt op de juiste manier verzameld
- Process mining is hiermee goed mogelijk
- Process mining heeft een duidelijke toegevoegde waarde, door het praktische resultaat en de what-if scenario’s die we kunnen doorrekenen.
0 reacties